

The best AI model for coding in 2026 is not a settled question, and any article telling you it is has either not tested the tools recently or is affiliating toward one answer. The honest picture is that Claude, GPT, and Gemini have each developed distinct strengths that show up differently depending on what type of coding work you are doing.
This guide is for developers and technically capable users who want a direct, benchmark-grounded answer rather than a marketing summary. It covers SWE-bench scores, real-world IDE integration, debugging quality, pricing, and the specific task types where each model actually wins; not just where each lab claims it does.
If you have read the guides on ChatGPT vs Claude: which AI assistant is actually better in 2026, Gemini vs ChatGPT for students, new AI models in 2026: GPT-5, Claude 4, Gemini 3, or AI tools for freelancing on Fiverr and Upwork, you already understand the general landscape. This article goes deeper into the coding-specific comparison that those guides touched without fully resolving.
What SWE-Bench Actually Measures (And Why It Has Limits)
Best AI Model for Coding 2026: Understanding the Benchmark Before the Numbers
SWE-bench Verified is the benchmark that comes up most often in coding AI comparisons, and it is genuinely the most meaningful one available. Unlike HumanEval, which tests whether a model can solve isolated programming puzzles, SWE-bench tests whether a model can resolve real GitHub issues from production repositories; the kind of messy, context-dependent bugs that developers deal with daily.
The scores as of May 2026 on stable production models:
- GPT-5.3 Codex: 85 percent
- Claude Opus 4.6: 80.8 percent
- Claude Sonnet 4.6: 79.6 percent
- Gemini 3.1 Pro: approximately 75 to 78 percent (varies by evaluator)
- Grok 4: 75 to 76.7 percent
Claude Mythos Preview, Anthropic’s unreleased next-generation model, scored 93.9 percent on SWE-bench Verified as of May 2026, which is a meaningful signal about where the ceiling is moving. Among stable, production-available models, GPT-5.3 Codex currently leads the SWE-bench leaderboard.
What these numbers do not capture:
SWE-bench measures autonomous issue resolution on isolated problems. It does not measure how a model reasons about vague specifications, how it handles architectural decisions across a large codebase, or how it explains code to a developer who needs to understand and maintain what the AI wrote. These dimensions matter in practice, and they do not show up in benchmark tables.
The metric that complements SWE-bench is LiveCodeBench, which tests competitive programming problems published after each model’s training cutoff, making it harder to game through memorization. Gemini 3.1 Pro leads LiveCodeBench with a Pro Elo rating approximately 200 points ahead of Claude Opus 4.6 and GPT-5.3 Codex. That result tells a different story from SWE-bench alone, and both data points together give a more accurate picture than either individually.
Claude Opus 4.6 and 4.7: Why Developers Trust It Most for Complex Work

Best AI Model for Coding Developers: The Claude Case
The most telling data point about Claude’s position in developer workflows is not a benchmark. It is that Claude powers Cursor, Windsurf, and Claude Code, the three tools that most professional developers in 2026 report using daily. When the companies building developer tools make a choice about which model to put at the center of their product, that is a signal that matters more than any single evaluation score.
Where Claude leads in real coding work:
Claude Opus 4.6 produces review comments that read as if they came from a thoughtful senior developer. When you ask it to refactor a component, explain an architectural trade-off, or identify why a specific pattern is problematic, the response has contextual depth that GPT’s more checklist-like style sometimes lacks. For complex refactoring tasks, Claude Opus 4.6 leads SWE-bench Pro, specifically, the harder subset of issues that require genuine architectural reasoning rather than pattern matching.
Claude Opus 4.7, the current latest release, achieves 87.6 percent on SWE-bench Verified and 64.3 percent on SWE-bench Pro, which tests particularly complex real-world issues. It can output 128,000 tokens in a single response, meaning it can generate a complete, well-structured codebase or a detailed technical specification without truncating.
Claude Code (the agentic CLI):
Claude Code is included in the Claude Pro plan at $20/month and runs in the terminal with full filesystem access, autonomous execution, and Model Context Protocol (MCP) tool support. It does not just suggest code; it can read your entire project, identify issues, make changes across multiple files, run tests, and iterate based on results, all within a single terminal session. This agentic workflow is significantly beyond what standard ChatGPT Plus provides in its basic chat interface.
The cost trade-off:
Claude Opus 4.6 is priced at $15 per million input tokens and $75 per million output tokens at the API level, the most expensive option in this comparison. Claude Sonnet 4.6, at $3/$15 per million tokens, delivers 79.6 percent on SWE-bench, within 1.2 points of Opus performance, at roughly 80 percent less cost. For most development workflows, Sonnet 4.6 is the more rational choice unless you are consistently working on the most architecturally complex problems, where Opus’s reasoning depth is the deciding factor.
GPT-5.4 and Codex: Where It Maintains Competitive Ground
Is GPT-5 the Best AI Model for Coding in 2026?
GPT-5.3 Codex currently leads the SWE-bench Verified leaderboard at 85 percent among stable production models. GPT-5.4, the broadly available version, sits close to Claude Opus on most coding benchmarks while offering workflow advantages that matter in specific developer contexts.
Where GPT wins in coding workflows:
GPT-5.4’s Code Interpreter executes Python code live within the chat session, displays results, handles debugging, and produces charts and data visualizations from code output; a capability Claude does not offer in standard chat. For data science, ML engineering, and any workflow where seeing live execution results accelerates development, this is a practical feature with no equivalent in Claude’s standard interface.
GPT-5.4 added native computer use capabilities and a 1 million token context window in Codex mode, making it viable for codebase-scale analysis that was previously out of reach. For DevOps workflows, terminal operations, and automated pipeline work, GPT-5.4 handles these particularly well.
For automated code review in CI pipelines, GPT-5.4 Mini (the lightweight, low-cost version) catches the most common issues: unused variables, potential null references, and obvious logic errors, at a fraction of the cost of any frontier model. For teams that want automated code quality checks without paying frontier pricing on every PR, this is a practical configuration.
GPT’s code review style:
GPT reviews tend to be more structured and checklist-oriented. They flag issues systematically but sometimes lack the contextual explanation that Claude provides. For junior developers who need to understand why something is a problem, Claude’s explanatory depth is more useful. For automated pipelines where speed and cost matter more than explanation quality, GPT’s style is well-suited.
Gemini 3.1 Pro: The Value Case Most Developers Are Underestimating
How Gemini 3.1 Pro for Coding Compares to Claude and GPT in 2026
Gemini 3.1 Pro does not lead the overall SWE-bench Verified leaderboard, but it leads LiveCodeBench, which measures algorithmic reasoning on novel problems rather than pattern-matched bug fixing. That distinction matters for competitive programmers, developers working on novel algorithm implementations, and anyone whose work requires genuine mathematical or logical reasoning about code structure rather than familiarity with common bug patterns.
The practical advantages:
Gemini 3.1 Pro offers the largest context window at 2 million tokens. In coding terms, this means it can process an entire monorepo in a single session, analyzing cross-file dependencies, identifying architectural inconsistencies, and suggesting refactors across a complete codebase without hitting context limits. For VS Code users working on mid-size projects, Gemini 3.1 Pro offers the strongest combination of performance and cost according to independent developer evaluations.
Pricing: At $2 per million input tokens and $12 per million output tokens, Gemini 3.1 Pro delivers near-frontier coding capability at approximately 60 percent of Claude Sonnet’s cost and significantly less than Claude Opus. For teams processing high volumes of code through API calls, this pricing difference compounds meaningfully over a month of usage.
Gemini CLI:
Google’s Gemini CLI tool provides a terminal-based coding agent similar in concept to Claude Code. It integrates particularly well with Google Cloud infrastructure and Google Workspace tooling. For teams already running on Google Cloud, this integration reduces context switching between coding tools and infrastructure management.
Where Gemini is weaker on coding:
Gemini sometimes over-explains simple issues while under-explaining complex ones in code review contexts. Its output style on coding tasks is less consistent than Claude’s; the quality varies more across different problem types. For developers who need reliable, predictable output on a wide range of coding tasks, Claude’s consistency is a practical advantage that benchmark scores do not capture.
DeepSeek V4 and Open-Source Alternatives: The Cost Equation Has Changed

The open-source coding model landscape improved significantly in 2026. DeepSeek V4 and Qwen 3.5, particularly the 397 billion parameter version, score within striking distance of Claude Sonnet and GPT-5.4 on HumanEval+, MBPP+, and SWE-bench. For developers and teams processing high volumes of routine coding tasks, this is a practical option worth considering seriously.
DeepSeek V4 via API costs approximately $0.27 per million tokens. For teams that use AI for mass test generation, boilerplate scaffolding, comment generation, and log analysis, running these tasks through DeepSeek while reserving Claude or GPT for complex reasoning work cuts total API costs by 50 to 70 percent compared to using a frontier model for everything.
The trade-off: open-source models are still less reliable than Claude Opus or GPT-5.4 on complex multi-step reasoning, nuanced architectural decisions, and the hardest SWE-bench problem categories. They are production-viable for a significant subset of coding tasks and not yet production-viable for the hardest subset. Using them strategically rather than universally is the sensible approach.
For freelancers and independent developers covered in the guide on AI tools to make money online without investment, DeepSeek V4 represents a zero-cost option for routine coding work that delivers professional-quality output without any subscription.
IDE Integration: Where You Use the Model Matters as Much as the Model Itself

Cursor, VS Code, and Claude Code for Developers in 2026
The editor or IDE you use determines which model you can access most conveniently, and that practical constraint is as important as any benchmark score for most developers.
Cursor (powered by Claude):
Cursor is the IDE that most professional developers in 2026 identify as their primary AI-assisted coding environment. It uses Claude Sonnet 4.6 and Opus 4.6 as its default models and offers multi-file editing, codebase-wide context, and autonomous agent modes that can execute tasks across an entire project. For developers willing to pay $20/month for the Pro tier, Cursor provides the most integrated Claude experience available outside of Claude Code directly.
GitHub Copilot (multi-model in 2026):
GitHub Copilot now supports multiple backend models, including GPT-5.4 and Claude Sonnet 4.6. The free tier, available to verified students and open-source maintainers through the GitHub Student Developer Pack, gives access to Copilot with GPT-4o as the default model. The paid Individual plan at $10/month unlocks the full model selection. For developers already in the GitHub ecosystem, Copilot’s integration with pull requests, code review, and repository-level context makes it a practical choice regardless of which underlying model you prefer.
Gemini in VS Code (Gemini CLI):
Google’s Gemini integration for VS Code provides terminal-based agentic coding with Gemini 3.1 Pro as the backend. For developers on Google Cloud infrastructure, the seamless handoff between code editing and cloud deployment is a practical workflow advantage. For developers outside the Google ecosystem, the integration advantage is less compelling.
For students and developers who have read the guide on best free AI tools for students, GitHub Copilot’s free student tier is the most accessible entry point to professional AI-assisted development at zero cost.
Code Review Quality: What Each Model Catches That Others Miss
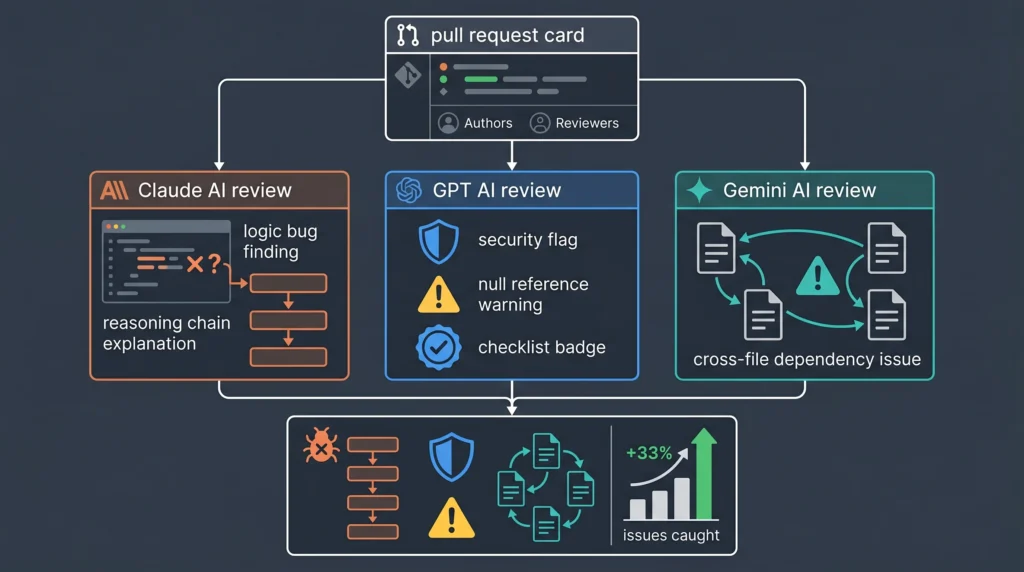
Based on research from teams running parallel multi-model code reviews, the pattern of what each model catches consistently differs:
Claude Opus 4.6 finds:
- Logic bugs that require reasoning about the intended behavior of the code
- Architectural problems: places where the design pattern choice creates future maintenance problems
- Security vulnerabilities that require understanding the data flow through multiple functions
GPT-5.4 finds:
- Security flaws and terminal-specific issues
- Common anti-patterns across a wide range of languages and frameworks
- Potential null references and type safety issues in dynamically typed codebases
Gemini 3.1 Pro finds:
- Algorithmic inefficiency in computationally intensive sections
- Cross-file dependency issues in large codebases, due to the 2-million-token context window
- Issues in recently updated libraries where their real-time search access provides current documentation context
The teams getting the strongest code review results run all three models in parallel on the same pull request and compare the suggestions. No single frontier model catches everything; running two or three models together catches roughly a third more issues than any individual model alone.
Pricing Summary: What Each Model Costs Per Million Tokens
For developers working at the API level or evaluating team plan costs, here is the current pricing structure:
Claude Opus 4.6: $15 input / $75 output per million tokens. Highest cost; highest reasoning depth for complex work.
Claude Sonnet 4.6: $3 input / $15 output per million tokens. Near-Opus performance (79.6 percent SWE-bench) at 80 percent cost reduction. Best Claude value for most development work.
GPT-5.4: $5 input / $30 output per million tokens. Strong across all coding tasks; leads SWE-bench among production models in Codex configuration.
Gemini 3.1 Pro: $2 input / $12 output per million tokens. Leads LiveCodeBench; largest context window; best cost-performance ratio at the frontier.
DeepSeek V4: Approximately $0.27 per million tokens. Near-frontier on routine coding tasks; significant cost saving for high-volume applications.
Practical note: For individual developers using chat interfaces at the $20/month plan level, these per-token costs do not apply directly, but for teams building AI-assisted tools, running automated review pipelines, or making architecture decisions about which models to integrate, the pricing differential across these options is substantial.
The Routing Approach: How Productive Developers Use Multiple Models
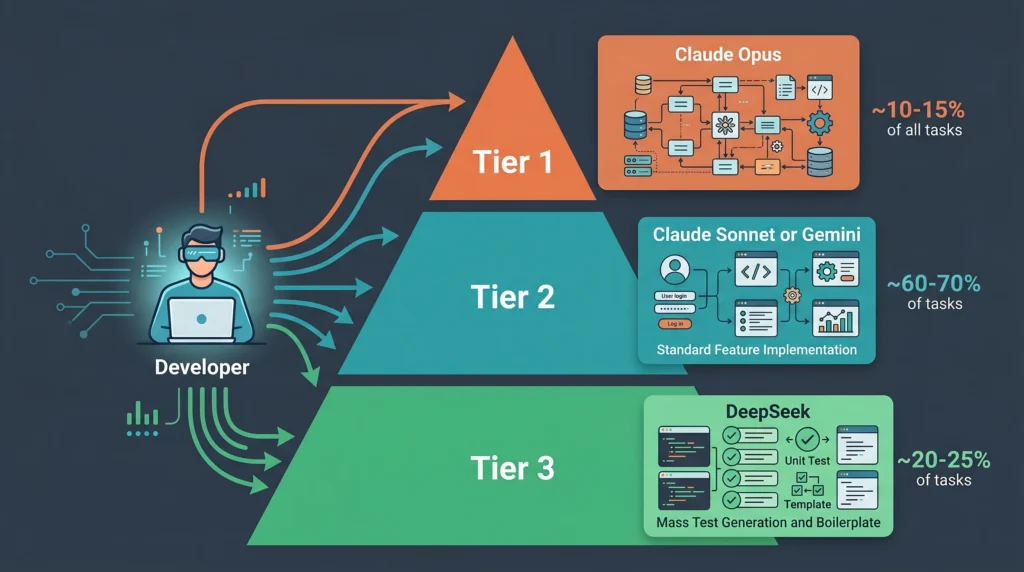
The most productive developers in 2026 are not choosing one model and committing to it. They route tasks to the model that handles them best, which is practical at current price points for most team budgets.
A tiered routing approach that reflects what high-performing development teams use:
Tier 1: Complex reasoning and architecture (10 to 15 percent of tasks) Model: Claude Opus 4.6 or 4.7 Use for: Architectural decisions, complex debugging, nuanced code review, difficult refactoring
Tier 2: Standard development work (60 to 70 percent of tasks) Model: Claude Sonnet 4.6 or Gemini 3.1 Pro Use for: Feature implementation, standard debugging, code explanation, documentation
Tier 3: High-volume, low-complexity tasks (20 to 25 percent of tasks) Model: GPT-5.4 Mini or DeepSeek V4 Use for: Mass test generation, boilerplate scaffolding, comment generation, log analysis
This tiered approach cuts total API costs by 50 to 70 percent compared to running every request through a frontier model, while maintaining near-frontier quality on the tasks that actually require it.
For freelance developers building income through client coding services, as covered in the AI tools for freelancing on Fiverr and Upwork guide, the Tier 2 configuration (Claude Sonnet 4.6 or Gemini 3.1 Pro for standard deliverables) represents the most practical balance of quality and cost for daily client work.
Frequently Asked Questions
Q. Which AI model has the highest coding benchmark score in 2026?
Among stable production models as of May 2026, GPT-5.3 Codex leads SWE-bench Verified at 85 percent, followed by Claude Opus 4.6 at 80.8 percent and Claude Sonnet 4.6 at 79.6 percent. Gemini 3.1 Pro leads LiveCodeBench, which tests algorithmic reasoning on novel problems. Claude Mythos Preview scored 93.9 percent on SWE-bench Verified but is not yet in general production release.
Q. Is Claude or GPT better for coding in practice?
Claude leads complex refactoring and architectural reasoning, and produces code with contextual explanations. GPT leads on live code execution via Code Interpreter, terminal, and DevOps workflows, and automated CI pipeline review at a lower cost. In practice, both are competitive; the better choice depends on your specific workflow and IDE preferences.
Q. What is Claude Code, and is it worth using?
Claude Code is Anthropic’s agentic terminal CLI, included in the Claude Pro plan at $20/month. It reads your filesystem, executes code, makes multi-file changes, runs tests, and iterates autonomously within a terminal session. It is the most capable standalone AI coding agent available to individual developers in 2026 and is worth using for complex, multi-step development tasks that benefit from autonomous execution.
Q. Is Gemini 3.1 Pro competitive with Claude and GPT for coding?
Yes, on several dimensions. It leads LiveCodeBench and offers the largest context window at 2 million tokens, making it the strongest option for large codebase analysis. Its pricing at $2/$12 per million tokens is significantly lower than Claude or GPT at comparable performance tiers. For mid-size projects on Google Cloud infrastructure, it is the most practical choice.
Q. How does DeepSeek V4 compare for coding tasks?
DeepSeek V4 is competitive with Claude Sonnet and GPT-5.4 on HumanEval+ and MBPP+ benchmarks at approximately $0.27 per million tokens. It is production-viable for routine coding tasks: test generation, boilerplate, code explanation, and log analysis. It is not yet reliable for the most complex architectural reasoning or SWE-bench’s hardest problem categories. The appropriate use case is high-volume routine work, not frontier-level complexity.
Q. Which AI coding model should I use if I am on a tight budget?
Claude Sonnet 4.6 on the Claude.ai free tier covers most everyday coding tasks at zero cost. GitHub Copilot’s free tier (available to students and open-source contributors) provides integrated editor support at no cost. For API usage at scale, Gemini 3.1 Pro at $2/$12 per million tokens or DeepSeek V4 at $0.27 per million tokens deliver strong results at minimum spend.
Q. What is the best AI coding assistant for VS Code users?
GitHub Copilot integrates most natively with VS Code and supports GPT-5.4 and Claude Sonnet 4.6 as backend models. Cursor is an alternative IDE built on VS Code’s foundation with deeper Claude integration. For developers committed to standard VS Code, Copilot is the most seamless option. For developers willing to switch editors for better AI integration, Cursor provides deeper agentic capabilities.
Q. Does the model choice matter more than the IDE integration?
For most developers, the IDE integration matters as much as the model in practice. A strong model accessed through a poorly integrated tool produces worse real-world results than a slightly weaker model accessed seamlessly within your existing workflow. Choosing the right tool involves both dimensions, not just the benchmark score of the underlying model.
Q. Which AI model is best for code review specifically?
No single model catches everything. Claude Opus 4.6 finds logic bugs and architectural issues. GPT-5.4 catches security flaws and common anti-patterns across languages. Gemini 3.1 Pro identifies cross-file issues in large codebases due to its context window advantage. Teams running parallel reviews with two or three models catch roughly a third more issues than any single model alone.
Q. How often do the benchmark rankings change in 2026?
Frequently. The coding model landscape shifted more in the five weeks between March and April 2026 than in the three months before that. Gemini 3.1 Pro’s release, GPT-5.3 Codex’s benchmark performance, and Claude Opus 4.7’s release all changed the relative standings within weeks of each other. This article reflects scores as of May 2026; checking the SWE-bench leaderboard directly is the most reliable way to verify current standings.
The Verdict: Which Model for Which Developer
Use Claude Opus 4.6 or 4.7 when: You are solving architecturally complex problems, doing serious refactoring work, or need the deepest available reasoning about code intent and design. If budget is not the primary constraint and you need the best available judgment on complex code, Opus is the choice.
Use Claude Sonnet 4.6 when: You want Claude’s reasoning quality for standard daily development work without Opus pricing. Sonnet delivers 79.6 percent on SWE-bench at 80 percent less cost; it handles the large majority of coding tasks at near-Opus quality.
Use GPT-5.4 when: You need live code execution in-session, you work in terminal and DevOps contexts, or you want broad framework coverage with structured review output. Codex configuration leads SWE-bench on automated issue resolution.
Use Gemini 3.1 Pro when: You are analyzing a large codebase that exceeds other models’ context limits, you want the best cost-performance ratio at the frontier, or your competitive programming and algorithmic work benefits from LiveCodeBench-level reasoning quality.
Use DeepSeek V4 when: High-volume routine coding tasks need to be cost-efficient, and you are willing to route the hardest problems to a more expensive frontier model.
